LLM Flashcards: learn how language models actually work.
A set of 330+ cards covering the full LLM stack, from tokenization and attention through RAG, agents, and inference. A clean diagram, a short explanation, and nothing you have to wade through. Built by a working LLM research lab, not a content farm.
Get the cards → See what’s inside
One-time purchase, lifetime updates included. Rated 5.0 out of 5 across 45 ratings, 96% five-star.

A few sample cards
Every card is self-contained: a diagram you could redraw on a whiteboard, plus a few sentences on what it means and why it matters. Scroll to browse →
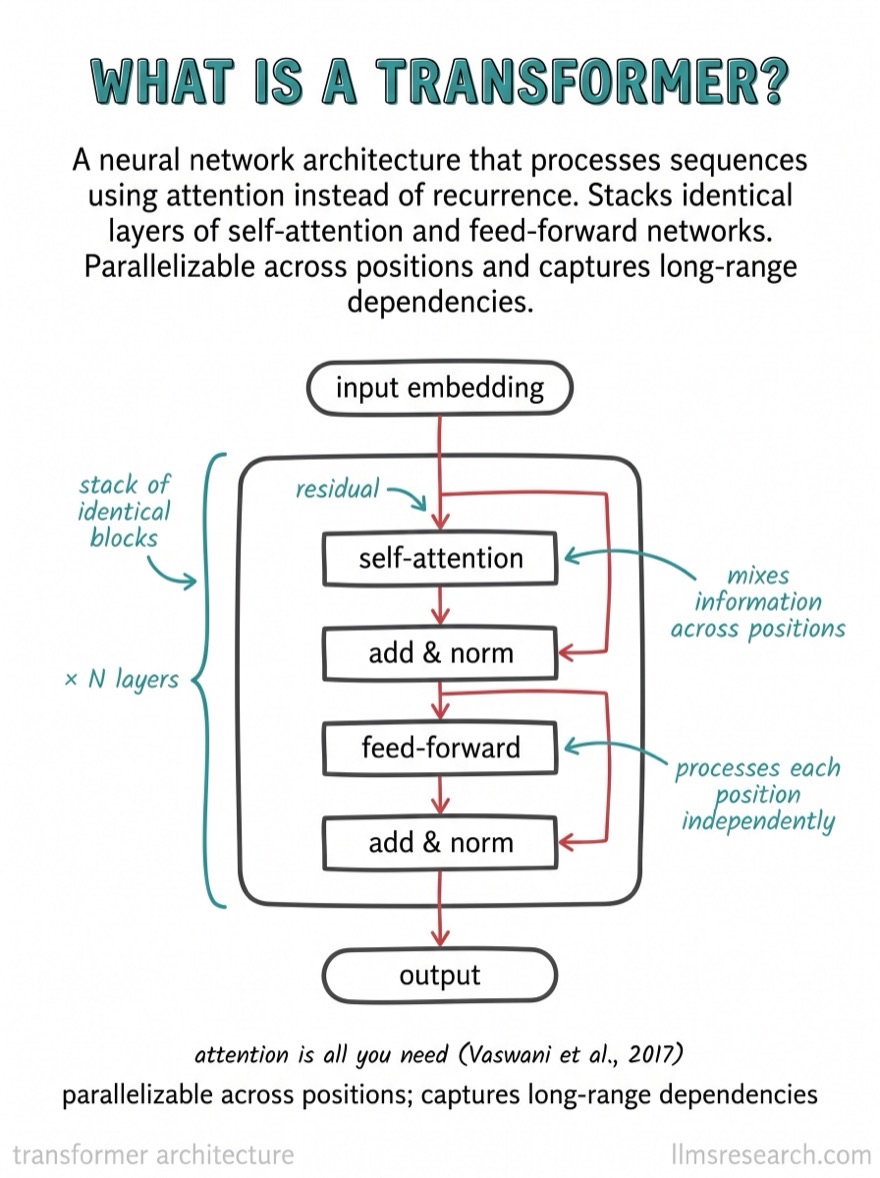
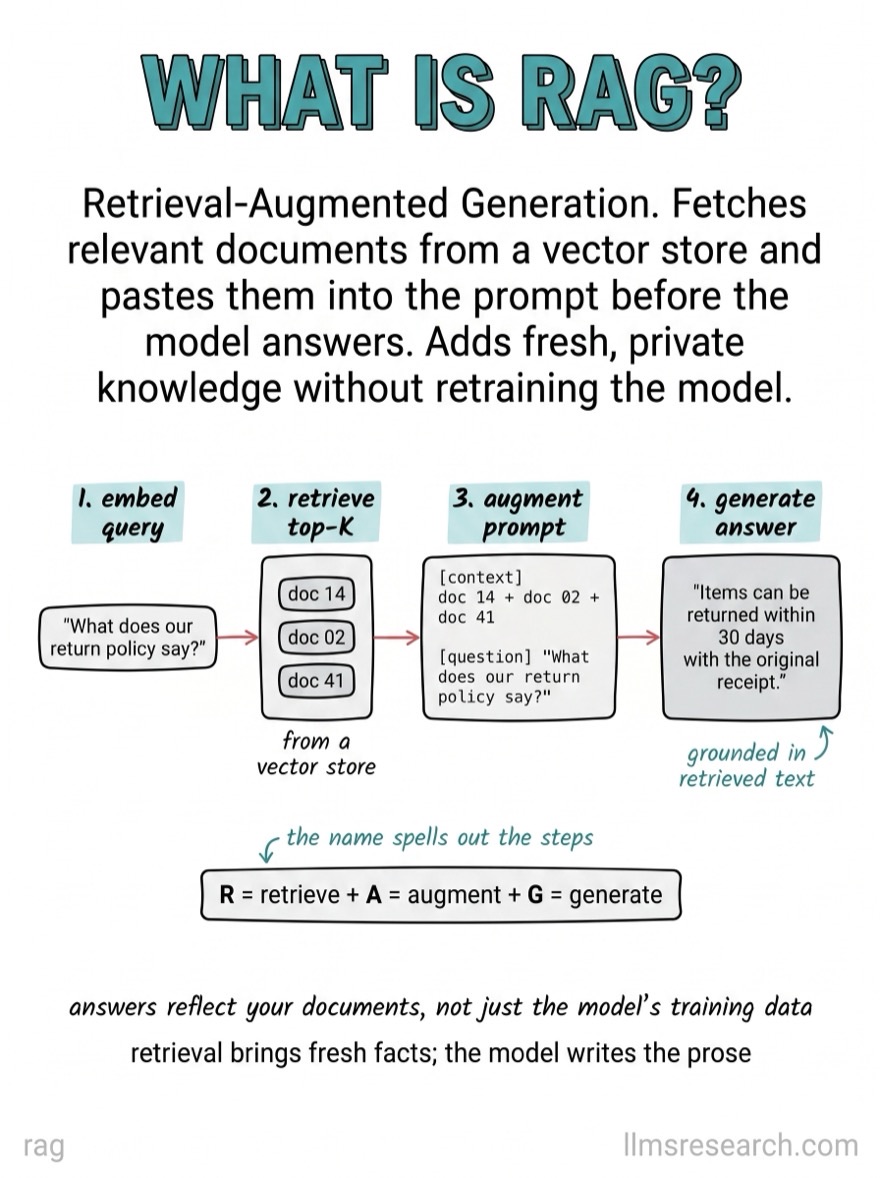
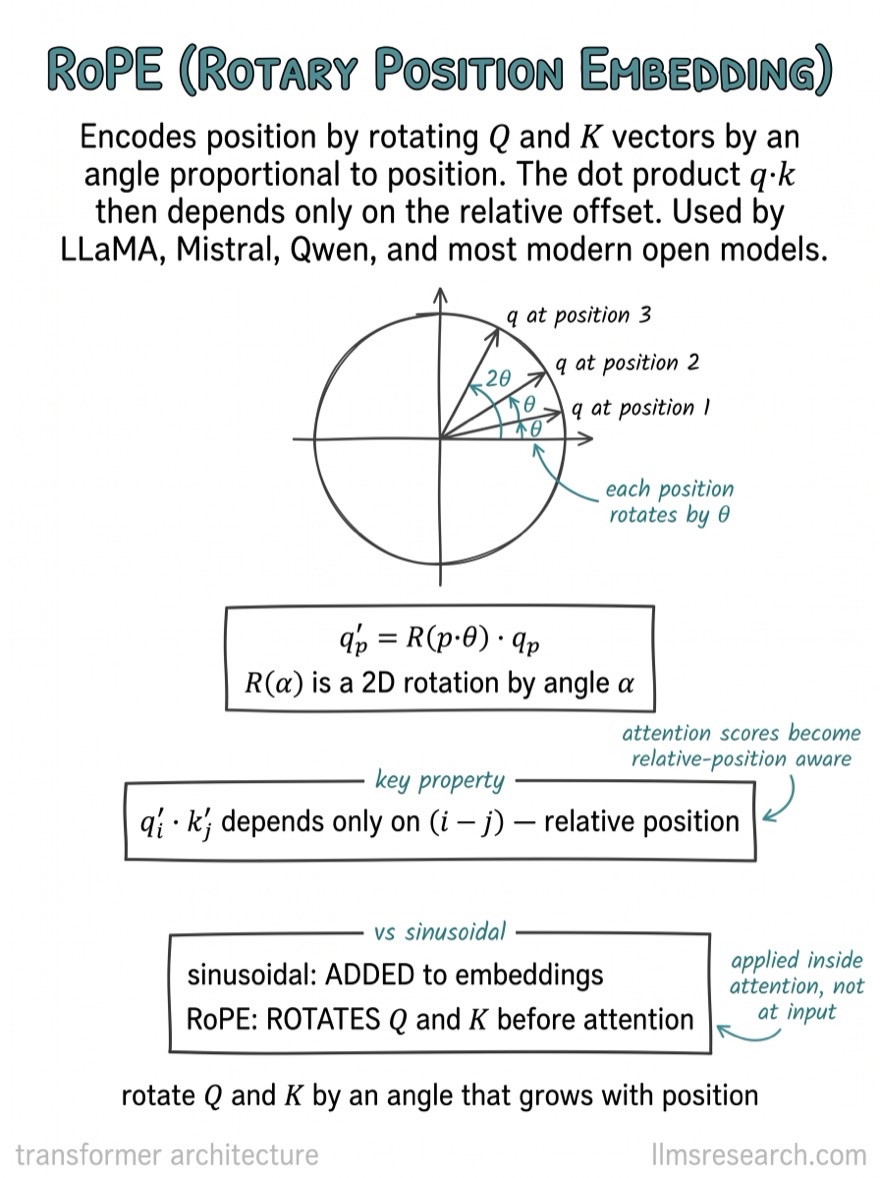
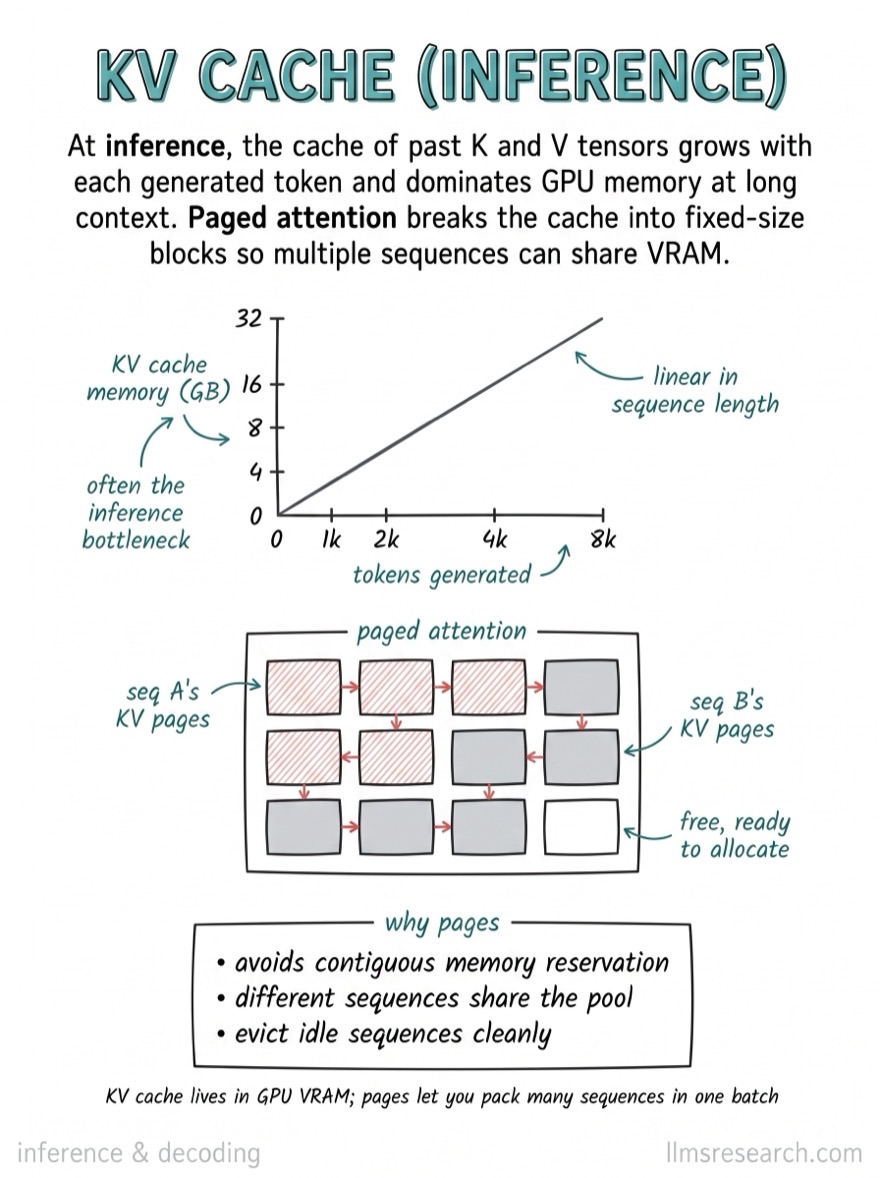
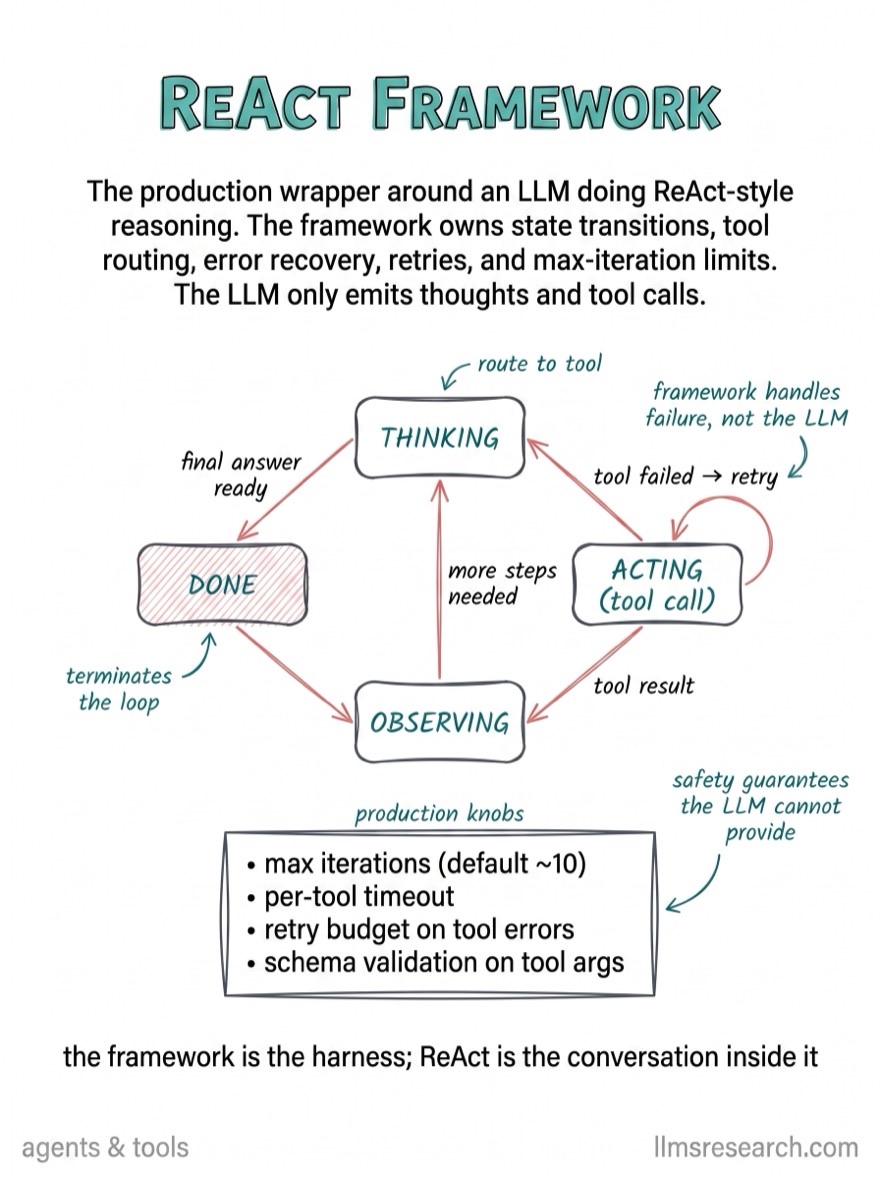
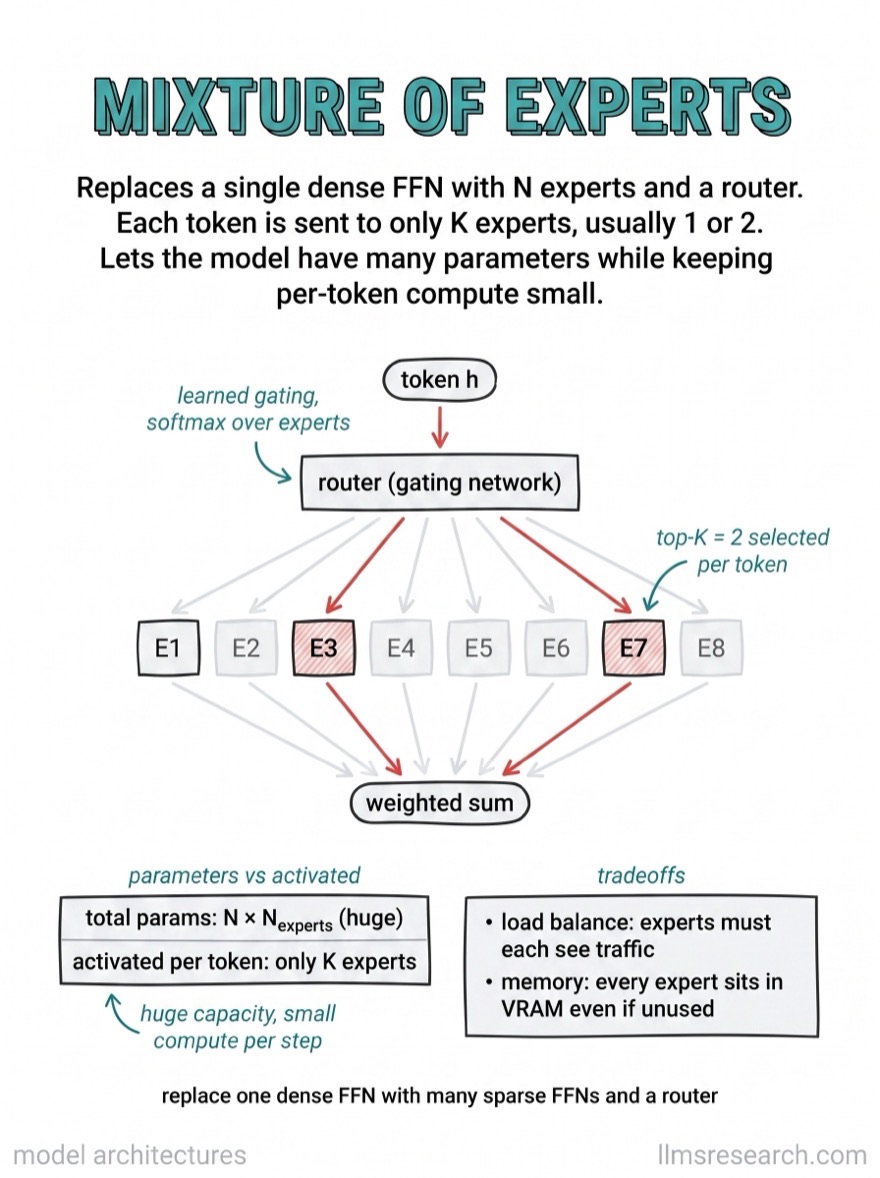
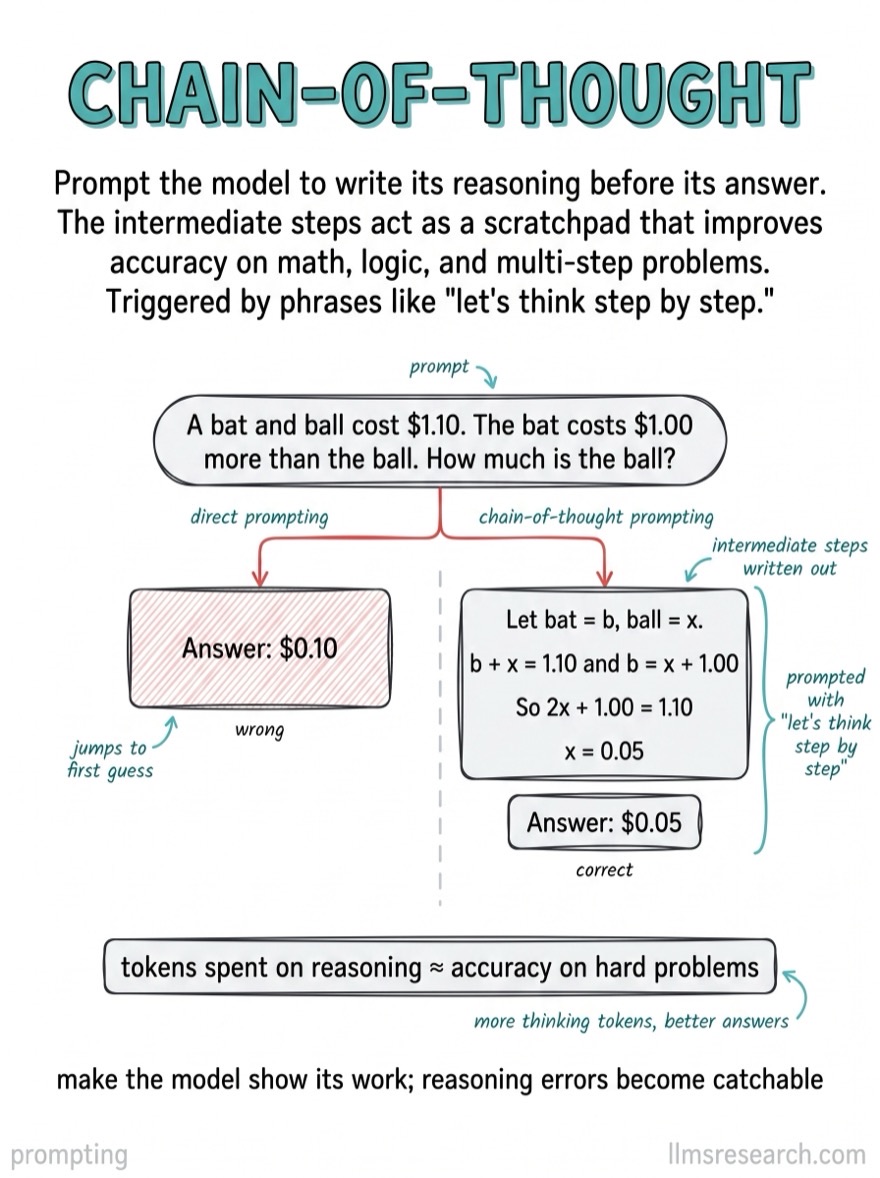
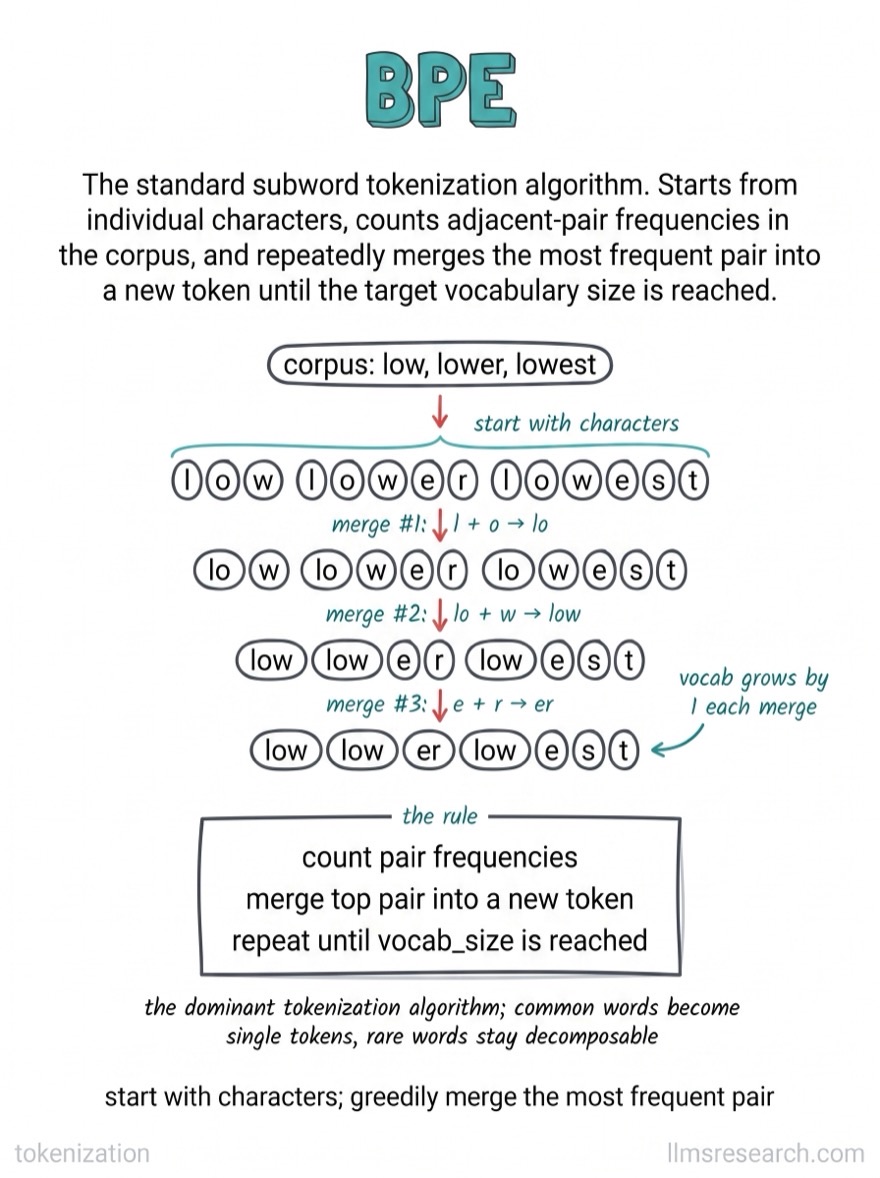


What’s inside
330+ cards across 22 topics, ordered so each one builds on the last. Read straight through to build a mental model from first principles, or jump to the topic you need.
- I.Tokenization. BPE, byte-level, vocabularies, special tokens, fertility. 12 cards
- II.Embeddings & retrieval. Vectors, similarity, vector search, BM25, ColBERT, rerankers. 14 cards
- III.Transformer architecture. Attention, QKV, positional encoding, RoPE, the full block. 30 cards
- IV.Model architecture variants. MoE, MLA, Mamba, linear attention, SwiGLU, RMSNorm. 16 cards
- V.Training fundamentals. Objectives, loss, optimizers, activations, backprop, grokking. 18 cards
- VI.Distributed training. Data, tensor, and pipeline parallelism, ZeRO, FSDP. 10 cards
- VII.Scaling laws. Chinchilla, compute-optimal training, emergence, test-time scaling. 10 cards
- VIII.Fine-tuning. SFT, LoRA, QLoRA, DoRA, adapters, model merging. 15 cards
- IX.RLHF & alignment. Reward models, PPO, DPO, GRPO, RLVR, reward hacking. 19 cards
- X.Inference & decoding. KV cache, sampling, speculative decoding, batching, caching. 19 cards
- XI.Quantization & efficiency. INT8/INT4, GPTQ, AWQ, BitNet, GGUF, distillation. 12 cards
- XII.Prompting. Few-shot, chain-of-thought, tree of thoughts, prompt optimization. 19 cards
- XIII.Reasoning. Reasoning models, long CoT, verifier search, MCTS, tool use. 15 cards
- XIV.Context management. Lost in the middle, compression, YaRN, KV eviction, context rot. 10 cards
- XV.Retrieval-augmented generation. Chunking, HyDE, GraphRAG, Self-RAG, agentic RAG. 24 cards
- XVI.Agents & tools. Function calling, MCP, computer use, orchestration, agent eval. 22 cards
- XVII.Multimodal. Vision transformers, VLMs, fusion, speech, diffusion, documents. 8 cards
- XVIII.Advanced concepts. Multimodal LLMs, CLIP, synthetic data, continual pretraining. 6 cards
- XIX.Evaluation & benchmarks. Perplexity, MMLU, GPQA, SWE-bench, needle-in-a-haystack. 16 cards
- XX.Safety & ethics. Hallucination, bias, watermarking, unlearning, oversight. 17 cards
- XXI.Interpretability. Mechanistic interp, probing, logit lens, induction heads, SAEs. 7 cards
- XXII.APIs & practical. Chat completion, structured outputs, batch, embeddings, routing. 13 cards
Who it’s for
- Engineers working with LLMs who want a clean visual reference to keep open while reading papers or model cards.
- Anyone preparing for an AI or ML engineering interview. The cards map to the concepts that actually come up: transformer internals, attention variants, KV cache, RAG, fine-tuning, inference trade-offs. Revise them with the Anki set in the weeks before.
- Students in NLP or deep-learning courses who think better through diagrams than dense paragraphs.
- Self-taught learners who have used an LLM API and want to understand what is actually happening underneath.
How to use it
- Read straight through, topic by topic, to build a foundation.
- Import the Anki set and review on your commute with spaced repetition.
- Print four cards per page for physical study, or a single card full size as a poster.
- Keep the PDF open as a reference while reading papers or model cards.
Questions
What formats do I get?
Three. A multi-page PDF organized by topic, high-resolution enough to print four cards per page, an Anki set (.apkg) for spaced-repetition review on desktop or mobile, and a zip of every card as a separate image.
Are these for beginners or experts?
Both, but most useful in the middle. If you have used an LLM API and want to understand what is happening underneath, this is built for you. The diagrams are approachable, but the technical depth assumes some ML background.
Is it good for interview prep?
Yes. The cards cover the concepts that come up in LLM and ML engineering interviews, and the Anki set makes them easy to revise with spaced repetition in the weeks before.
How often does the set update?
New cards are added as new techniques and research land. Past buyers get every update free, with no expiry and no resubscription.
Who made it?
These cards started as study notes inside LLMs Research, an independent applied research lab publishing on KV cache compression, adaptive compute, and multi-agent systems. They grow alongside the research work. You can read more about the lab.
What buyers say
“Gold standard! Cards are amazing to revise LLMs concepts. I now feel much more confident in my ability to explain LLM concepts in the interviews.”
“#1 thing to revise LLMs concepts before any AI interview.”
“Helped me crack interview, thanks!”
“Absolutely amazing, love the visuals!”
“A must have flashcards if you are into AI!”
“Nice cards. Easy to remember concepts.”
“Very nice card! and, they get contuosly updated as field is moving!”
Quotes from verified Gumroad ratings, unedited.
Free PDF
Not getting the full set today?
Subscribe to the LLMs Research newsletter and we’ll send you 30 of the visual cards as a free PDF.
Free. Unsubscribe anytime.
One last step
We opened Substack in a new tab with your email filled in. Click Subscribe there (the free plan is all you need) and your PDF arrives by email. Not there in a minute? Check spam.