Prefill and decode
Generating text with a transformer happens in two phases. First, prefill: the model reads the entire prompt in one parallel pass and produces the first new token. Then, decode: the model generates the rest one token at a time, each new token appended to the sequence and fed back in to produce the next. The KV cache is about making the decode phase efficient, and decode is where models spend most of their time during generation.
The repeated work
Recall how attention works: to process a token, the model compares its query against the keys of all previous tokens and takes a weighted sum of their values. During decode, the model generates token 2, then token 3, then token 4, running attention each time over everything so far.
Here is the waste. When the model generates token 1000, the key and value vectors for tokens 1 through 999 are byte-for-byte identical to what they were when it generated token 999. Their inputs did not change, so their keys and values cannot have changed. Recomputing them at every step means redoing nearly all the work on every single token.
The fix: cache K and V
The keys and values of past tokens are constant once computed, so store them. At each decode step, compute the query, key, and value for only the one new token, append its key and value to the running cache, and reuse all the stored ones. That cache is the KV cache.
Note that only keys and values are cached, not queries. Each new token needs its own query to ask its own question of the past, but it never needs the past tokens' queries again. Keys and values are what the past offers; queries are what the present asks.
The complexity argument
The cache turns a cubic cost into a quadratic one. Without it, generating token \(t\) requires recomputing attention over all \(t\) previous tokens, so producing a sequence of length \(n\) costs
With the cache, each new token only attends to the stored keys and values, costing \(O(t)\) at step \(t\), so the whole sequence costs
Dropping a factor of \(n\) is the difference between generation being practical and being hopeless. This is why every production serving system uses a KV cache; it is not an optional optimization but a structural one.
How big does it get?
The cache buys its speed with memory, and the bill is large. For every token in the context, the model must store a key vector and a value vector, in every layer, for every key/value head. The total size is:
The leading 2 is for keys and values. The cache grows linearly with three things at once: sequence length, batch size, and model depth. That triple dependence is why long context and high concurrency are both hard, and why they are hard together.
A worked calculation
Take a 7-billion-parameter model in the LLaMA-2 style: 32 layers, 32 key/value heads, head dimension 128, stored in 16-bit precision (2 bytes). Per token, the cache holds
Multiply by context length, for a single sequence:
| Context length | KV cache size |
|---|---|
| 1,024 tokens | 0.5 GB |
| 4,096 tokens | 2.0 GB |
| 8,192 tokens | 4.0 GB |
| 32,768 tokens | 16.0 GB |
The model's own weights are about 13 GB in 16-bit. So at a 32K context, the KV cache for a single request exceeds the size of the entire model. And that is one user. Serve a batch of them and the cache, not the weights, is what fills the GPU and caps how many requests you can run at once. This single table explains why long-context pricing is what it is.
Weights are loaded once and shared across all requests. The KV cache is per-request and grows with every token generated. Past a modest context length it dominates memory, and memory is what limits batch size, which is what limits throughput, which is what sets cost. Optimizing the KV cache is therefore one of the highest-leverage levers in LLM serving.
Keeping it under control
Because the cache is the bottleneck, a large share of inference research targets it directly.
- Grouped-query and multi-query attention. Let many query heads share a smaller number of key/value heads. A model with 64 query heads and 8 key/value heads shrinks its cache by 8× with little quality loss. This is now standard in large models. See the variants table in how attention works.
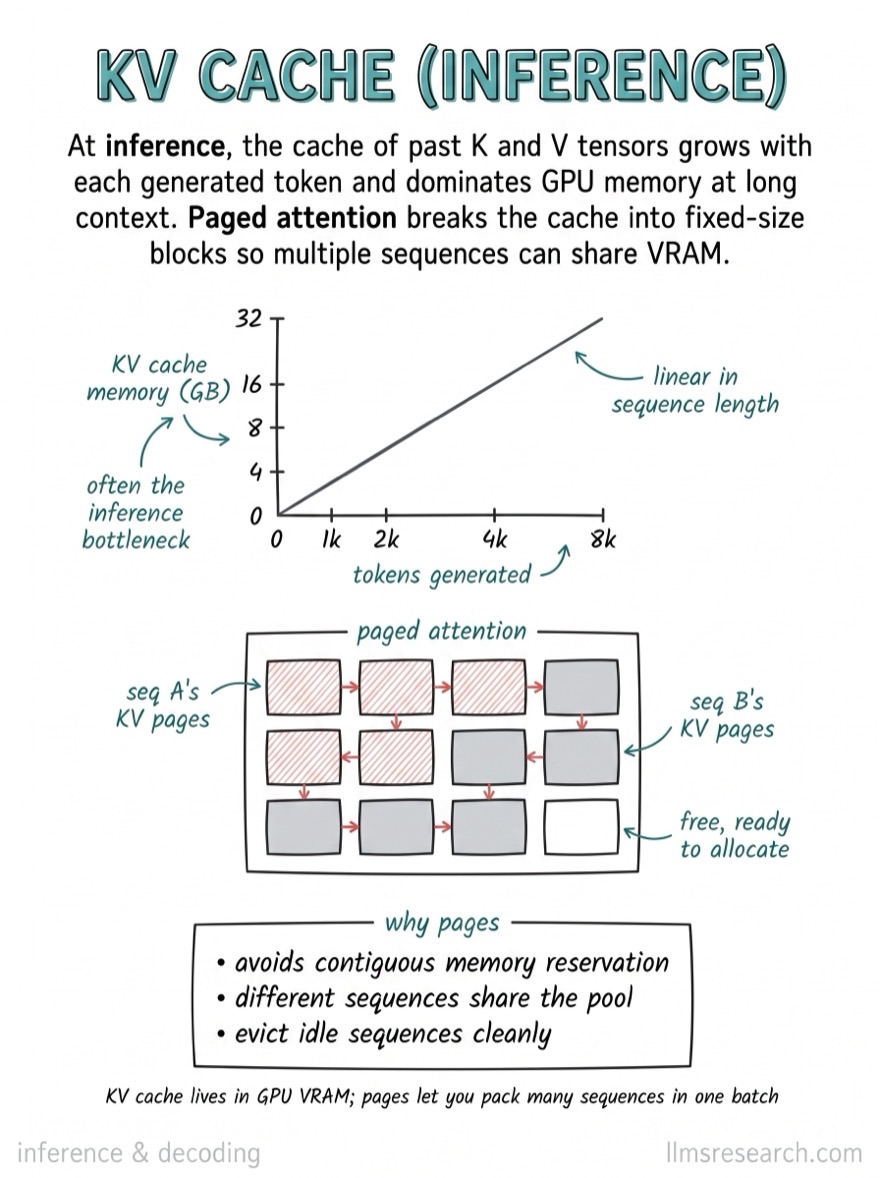
- Paged attention. Manage the cache in fixed-size blocks like operating-system virtual memory, instead of one contiguous region per request. This eliminates the fragmentation and over-allocation that otherwise waste large fractions of memory, and is the core idea behind high-throughput serving systems [1].
- Quantizing the cache. Store keys and values in 8 or 4 bits instead of 16, cutting size by 2× to 4× for a small accuracy cost.
- Eviction and compression. Not every past token matters equally. Eviction policies drop low-attention tokens; compression schemes shrink what is stored. This is where our lab's KV cache compression work focuses: how far the cache can be reduced before downstream quality degrades, which directly sets how cheaply long-context models can be served.
Inference internals, one card at a time
The KV cache, attention variants, quantization, and speculative decoding are covered in the LLM Flashcards: 330+ visual cards, as a PDF and an Anki set.
See the cards →References
- Kwon et al. Efficient Memory Management for Large Language Model Serving with PagedAttention. SOSP, 2023. The vLLM paper.
- Ainslie et al. GQA: Training Generalized Multi-Query Transformer Models. 2023.
- Shazeer. Fast Transformer Decoding: One Write-Head is All You Need. 2019.