What interviews actually test
The mistake most candidates make is preparing to recite. They memorize that the transformer was introduced in 2017 and that RAG stands for retrieval-augmented generation, then freeze when asked why attention is divided by the square root of the key dimension. Interviews for LLM-adjacent roles test whether you understand how the pieces fit and where the trade-offs lie. The single best predictor of how you will do is whether you can explain each core concept in two plain sentences, from memory, without reaching for jargon. If you can, the rest follows.
The topic map
Questions cluster into a handful of areas. You do not need every one in depth for every role, but a competent answer in each is the baseline that separates a strong candidate from a shaky one.
| Area | You should be able to explain |
|---|---|
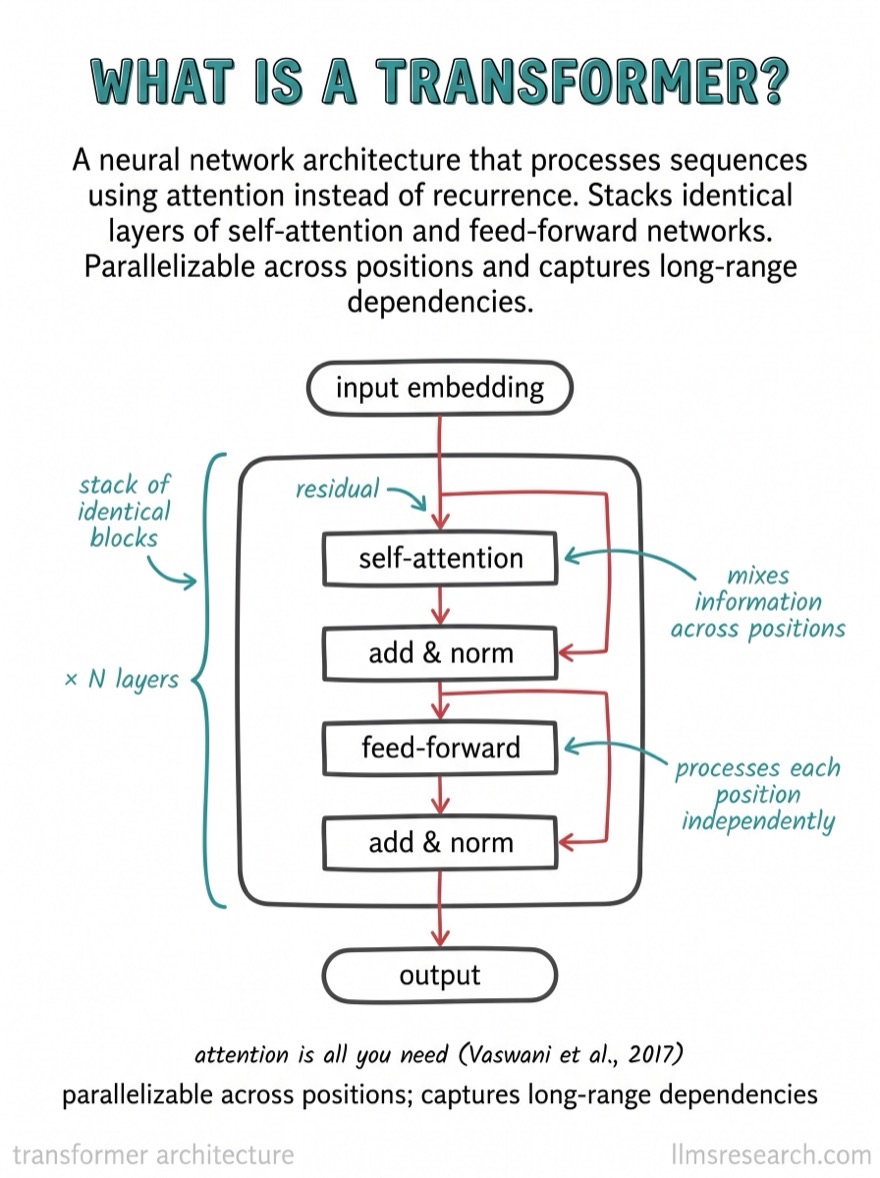
| Transformer basics | Attention, query/key/value, residuals, the feed-forward layer, why it replaced RNNs |
| Attention & efficiency | Multi-head vs grouped-query vs multi-query, the √dₖ scaling, the O(n²) cost |
| Tokenization & embeddings | What a token is, why BPE, what an embedding represents, positional encoding |
| Training & alignment | Pretraining vs fine-tuning, RLHF and DPO, LoRA |
| Retrieval & agents | How RAG works end to end, when to use it, function calling and agent loops |
| Inference | KV cache, sampling and temperature, speculative decoding, what drives latency and cost |
| Judgment | "A team wants to do X, how would you approach it?" Reasoning about trade-offs, not recall |
Question bank with answers
Here are questions that come up often, each with the kind of crisp answer an interviewer is listening for. Notice that none of them are longer than a few sentences. Brevity that shows understanding beats a rambling tour.
Why divide attention scores by the square root of the key dimension?
Because the dot product of two \(d_k\)-dimensional vectors has variance proportional to \(d_k\), so as the dimension grows the scores grow with it and push the softmax into a near one-hot regime where gradients nearly vanish. Dividing by \(\sqrt{d_k}\) restores roughly unit variance and keeps the softmax in a trainable range.
What is the KV cache and why does it matter?
During generation, the keys and values of past tokens never change, so they are cached and reused instead of recomputed at every step. This turns per-step cost from quadratic to linear in sequence length. It matters because the cache grows with length, batch, and depth, and at long context it becomes the largest consumer of GPU memory, capping how many requests you can serve.
RAG or fine-tuning for a knowledge base that changes weekly?
RAG. The information moves, so you want to update documents, not retrain weights. Fine-tuning to inject changing facts means retraining forever. Fine-tuning is for behavior and format, not for facts that move.
What does temperature do?
It scales the logits before the softmax. Lower temperature sharpens the distribution toward the most likely tokens, making output more deterministic; higher temperature flattens it, making output more diverse and more random. At temperature 0 the model is greedy.
Encoder-only vs decoder-only?
Encoder-only models like BERT attend bidirectionally and are trained to fill in masked tokens, which makes them strong at understanding tasks. Decoder-only models like GPT attend only to past tokens and are trained to predict the next token, which makes them generators. The difference is essentially the attention mask.
Do not read the answers and nod. Cover them, ask yourself each question aloud, and only then check. The gap between "I recognized that" and "I could say that" is exactly the gap an interview exposes.
The study method that works
Two techniques, both well supported by how memory actually works, do most of the heavy lifting.
Active recall. Producing an answer from memory strengthens it far more than re-reading. Passive review creates a feeling of familiarity that is easily mistaken for knowledge, and that illusion collapses under interview pressure. Every concept you study should end with you closing the source and explaining it out loud.
Spaced repetition. Review a concept just as you are about to forget it, on an expanding schedule, and it moves into durable memory with far less total effort than cramming. Tools like Anki schedule this automatically, which is why a flashcards with an Anki export is a natural fit for interview prep.
Why spaced repetition
Memory of a new fact decays roughly exponentially, the classic forgetting curve. Each well-timed review flattens the curve, so the fact decays more slowly afterward. Cramming stacks all your reviews at once, on the steepest part of the curve, where they overlap and waste effort. Spacing them out, a few minutes a day over two weeks, places each review where it does the most good. The same total study time produces dramatically better retention when it is distributed rather than massed.
A two-week plan
- Days 1 to 4 — Fundamentals. Transformers, attention, tokenization, embeddings. Get the mental model solid before anything builds on it. End each day explaining one concept aloud.
- Days 5 to 8 — Training and adaptation. Pretraining, fine-tuning, LoRA, RLHF, and RAG. These are where "how would you build X" questions live.
- Days 9 to 11 — Inference and efficiency. KV cache, sampling, quantization, latency and cost.
- Days 12 to 14 — Recall and judgment. Review weak spots with spaced repetition, and practice the open-ended "how would you approach this" questions out loud, ideally with someone else listening.
What separates strong candidates
- They reason about trade-offs. Asked to design something, a strong candidate names the options, states what each costs, and justifies a choice. A weak one recites the one approach they know.
- They say "I don't know" cleanly. Then reason from first principles toward a plausible answer. Bluffing is obvious and fatal; honest reasoning is impressive.
- They use precise words. "The cache grows linearly with sequence length" lands; "it gets big" does not.
- They can draw it. Interviewers often ask you to sketch attention or a RAG pipeline. If you have studied with diagrams, you can reproduce one on the whiteboard, which is exactly why visual study pays off here.
A revision set built for exactly this
The LLM Flashcards are 330+ visual cards covering every topic above, with an Anki set included so the spaced repetition runs itself. Built by a working LLM research lab.
See the cards →